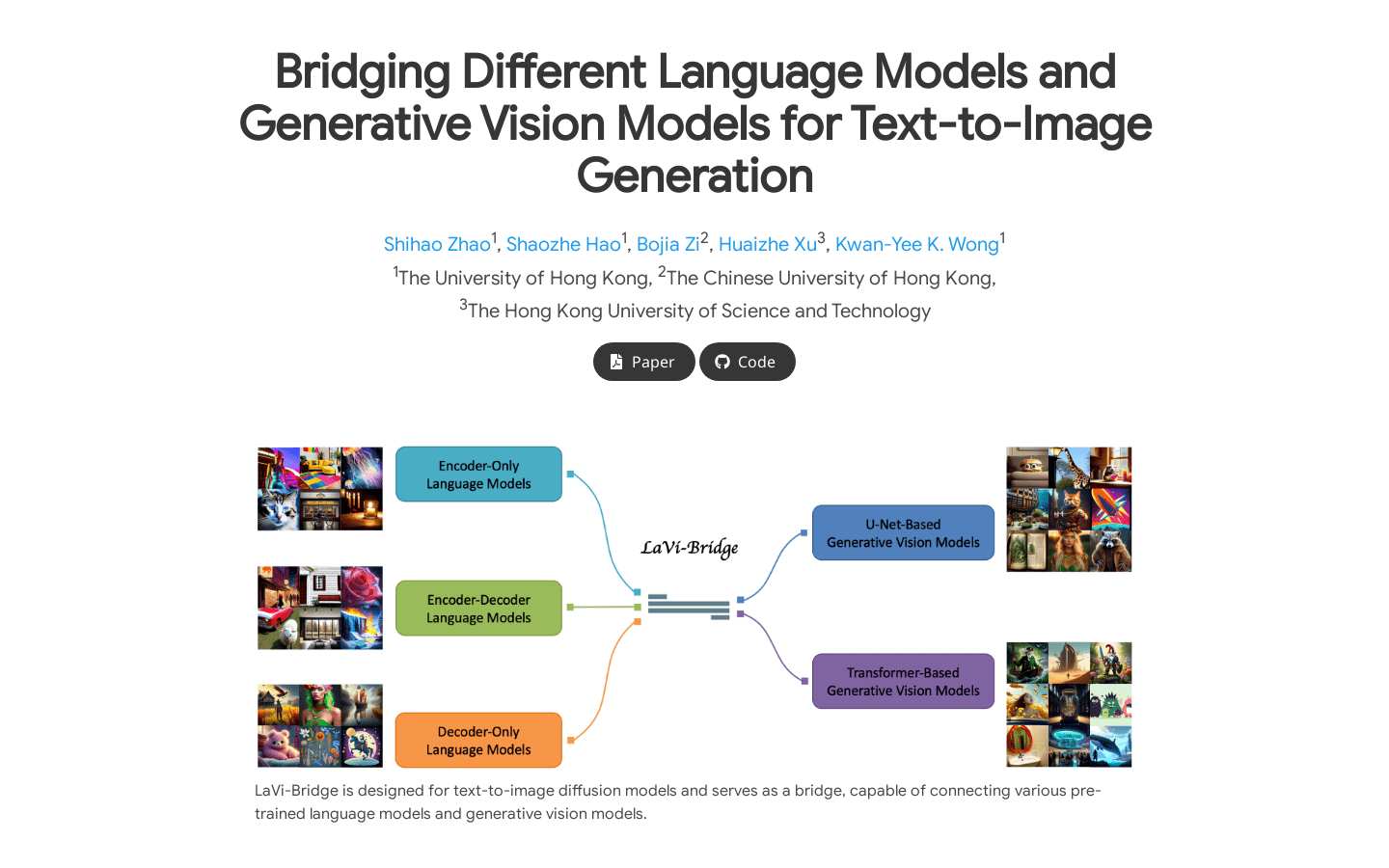

LaVi-Bridge
LaVi-Bridge是一种针对文本到图像扩散模型设计的桥接模型,能够连接各种预训练的语言模型和生成视觉模型。它通过利用LoRA和适配器,提供了一种灵活的插拔式方法,无需修改原始语言和视觉模型的权重。该模型与各种语言模型和生成视觉模型兼容,可容纳不同的结构。在这一框架内,我们证明了通过整合更高级的模块(如更先进的语言模型或生成视觉模型)可以明显提高文本对齐或图像质量等能力。该模型经过大量评估,证实了其有效性。
需求人群:
“LaVi-Bridge可用于文本到图像生成任务,特别是在需要集成更先进语言模型或视觉模型的场景。”
使用场景示例:
使用LaVi-Bridge将GPT-3语言模型与Stable Diffusion视觉模型集成,生成高质量图像
利用LaVi-Bridge将Llama语言模型与PixArt视觉模型连接,提高文本描述与生成图像的匹配度
通过LaVi-Bridge框架,快速评估不同语言模型和视觉模型在文本到图像生成任务上的性能
产品特色:
连接不同的语言模型和生成视觉模型
通过LoRA和适配器实现灵活性和插拔式集成
提高文本描述与生成图像的对齐度
提升图像质量
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END