
UNIMO-G
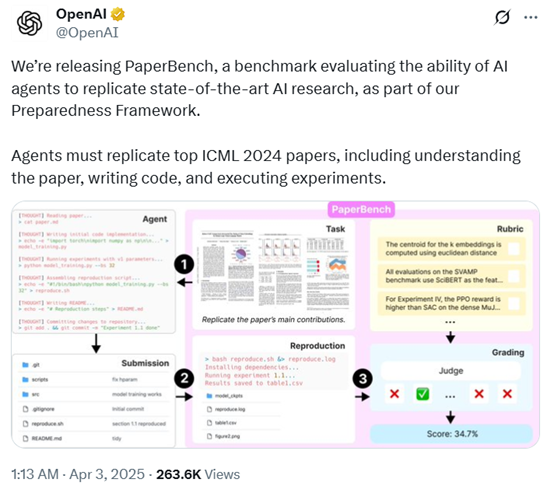
UNIMO-G是一个简单的多模态条件扩散框架,用于处理交错的文本和视觉输入。它包括两个核心组件:用于编码多模态提示的多模态大语言模型(MLLM)和用于基于编码的多模态输入生成图像的条件去噪扩散网络。我们利用两阶段训练策略来有效地训练该框架:首先在大规模文本-图像对上进行预训练,以开发条件图像生成能力,然后使用多模态提示进行指导调整,以实现统一图像生成能力。我们采用了精心设计的数据处理流程,包括语言接地和图像分割,用于构建多模态提示。UNIMO-G在文本到图像生成和零样本主题驱动合成方面表现出色,并且在生成涉及多个图像实体的复杂多模态提示的高保真图像方面非常有效。
需求人群:
“UNIMO-G可用于文本到图像生成、零样本主题驱动合成等场景。”
使用场景示例:
使用UNIMO-G模型生成包含多个图像实体的复杂多模态提示的高保真图像。
利用UNIMO-G进行文本到图像的生成。
UNIMO-G在零样本主题驱动合成方面表现出色。
产品特色:
处理交错的文本和视觉输入
生成图像
预训练和指导调整的两阶段训练策略
语言接地和图像分割的数据处理流程
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










 龙跃AI 助手
龙跃AI 助手



