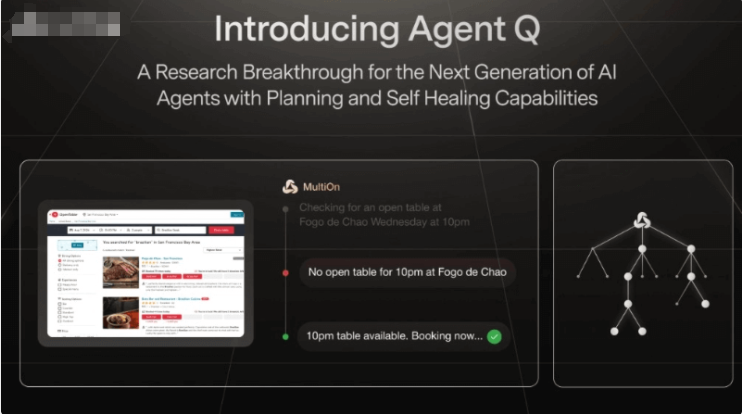
AI应用 第10页
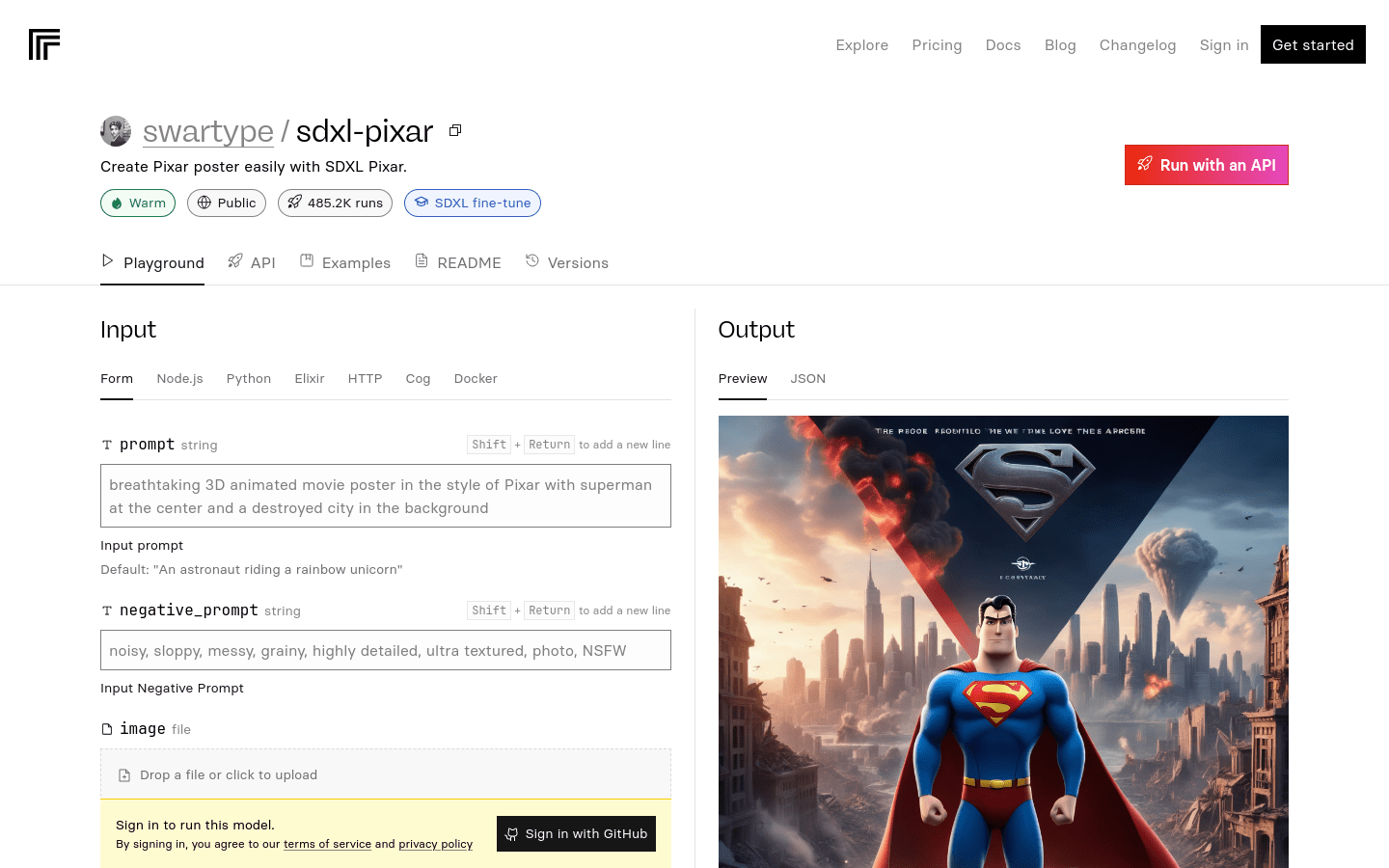
SDXL Pixar
SDXL PixarReplicate上的“SDXL fine-tunes”收藏包含了一系列基于SDXL模型的精选微调模型。这些微调模型利用大型生成模型SDXL,针对特定的视觉风格、内容或主题进行了优化和调整,以产生高质量...

MoMA
MoMAMoMA Personalization 是一款基于开源 Multimodal Large Language Model (MLLM) 的个性化图像生成工具。它专注于主题驱动的个性化图像生成,可以根据参考图像和文本提示生成高质量、保留目...
Diffusion-RWKV
Diffusion-RWKVDiffusion-RWKV是一种基于RWKV架构的扩散模型,旨在提高扩散模型的可扩展性。它针对图像生成任务进行了相应的优化和改进,可以生成高质量的图像。该模型支持无条件和类条件训练,具...

ApolloAI
ApolloAIApolloAI是一款人工智能平台,提供AI图像、视频、音乐、语音合成等功能。用户可以通过文本或图片输入生成多种类型的内容,具备商业使用权。定价灵活,提供订阅和一次性购买两种模式。 ...
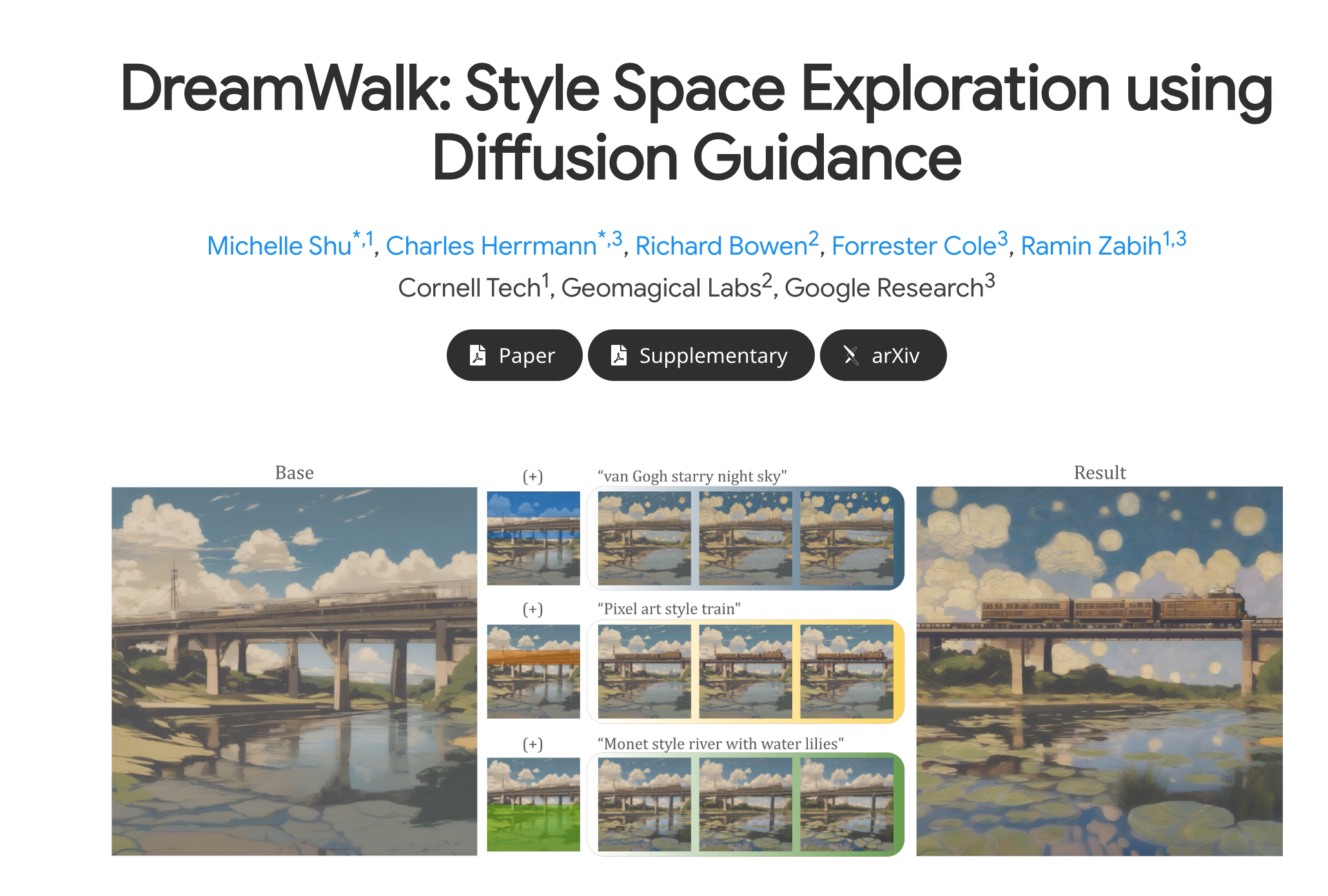
DreamWalk
DreamWalkDreamWalk是一种基于扩散指引的文本感知图像生成方法,可对图像的风格和内容进行细粒度控制,无需对扩散模型进行微调或修改内部层。支持多种风格插值和空间变化的引导函数,可广泛应用于...
VAR
VARVAR是一种新的视觉自回归建模方法,能够超越扩散模型,实现更高效的图像生成。它建立了视觉生成的幂律scaling laws,并具备零shots的泛化能力。VAR提供了一系列不同规模的预训练模型,供用户探索...
Gulf Picasso
Gulf PicassoGulf Picasso是一款基于人工智能的免费图像和头像生成工具。通过我们先进的AI技术,您可以从文字生成图片。无论是个性化头像生成还是类似DALL-E和PicsArt的数字艺术工具,我们满足...
InstantStyle
InstantStyleInstantStyle 是一个通用框架,利用两种简单但强大的技术,实现对参考图像中风格和内容的有效分离。其原则包括将内容从图像中分离出来、仅注入到风格块中,并提供样式风格的合成和...

MiniGemini
MiniGeminiMini-Gemini是一个多模态视觉语言模型,支持从2B到34B的系列密集和MoE大型语言模型,同时具备图像理解、推理和生成能力。它基于LLaVA构建,利用双视觉编码器提供低分辨率视觉嵌入和高分...
TextCraftor
TextCraftorTextCraftor是一种创新的文本编码器微调技术,能够显著提升文本到图像生成模型的性能。通过奖励函数优化,它改善了图像质量与文本对齐,无需额外数据集。 需求人群: '用于文本到图...
搜索