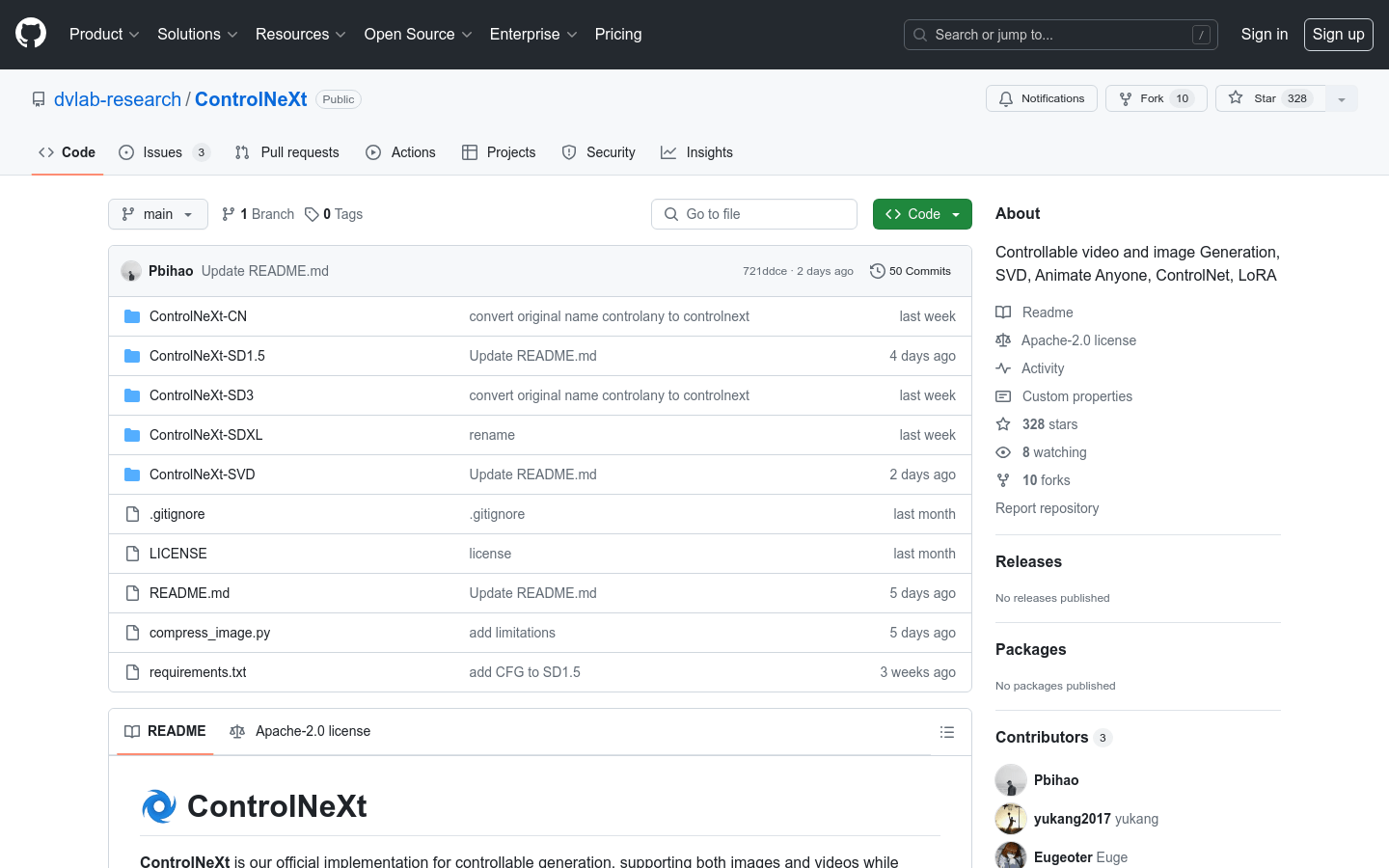

ControlNeXt
ControlNeXt是一个开源的图像和视频生成模型,它通过减少高达90%的可训练参数,实现了更快的收敛速度和卓越的效率。该项目支持多种控制信息形式,并且可以与LoRA技术结合使用,以改变风格并确保更稳定的生成效果。
需求人群:
“ControlNeXt适合需要生成高质量图像和视频内容的专业人士和研究人员,如动画制作者、游戏开发者、视觉效果设计师等。它的高效性和可控性为创意产业提供了强大的工具。”
使用场景示例:
生成受人类姿势序列控制的视频,如AnimateAnyone项目
使用Stable Diffusion 1.5进行可控图像生成,具有较少的可训练参数和更快的收敛速度
利用Stable Diffusion XL进行更高效的大尺寸图像生成
产品特色:
支持图像和视频的可控生成
减少高达90%的可训练参数,提高训练效率
与LoRA技术结合,实现风格变化和稳定生成
基于Stable Video Diffusion的简洁架构
适用于不同分辨率和需求的多个模型版本,如ControlNeXt-SD1.5和ControlNeXt-SDXL
持续迭代开发,代码和模型可能随时更新
使用教程:
1. 访问ControlNeXt的GitHub页面并克隆或下载代码
2. 阅读README文件了解安装和配置要求
3. 根据需要选择合适的模型版本,如ControlNeXt-SD1.5或ControlNeXt-SDXL
4. 准备输入数据,如姿势序列或风格参数
5. 运行模型生成图像或视频
6. 根据生成结果调整参数以优化输出
7. 将生成的图像或视频应用于所需的项目或研究中
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
















 龙跃AI 助手
龙跃AI 助手

