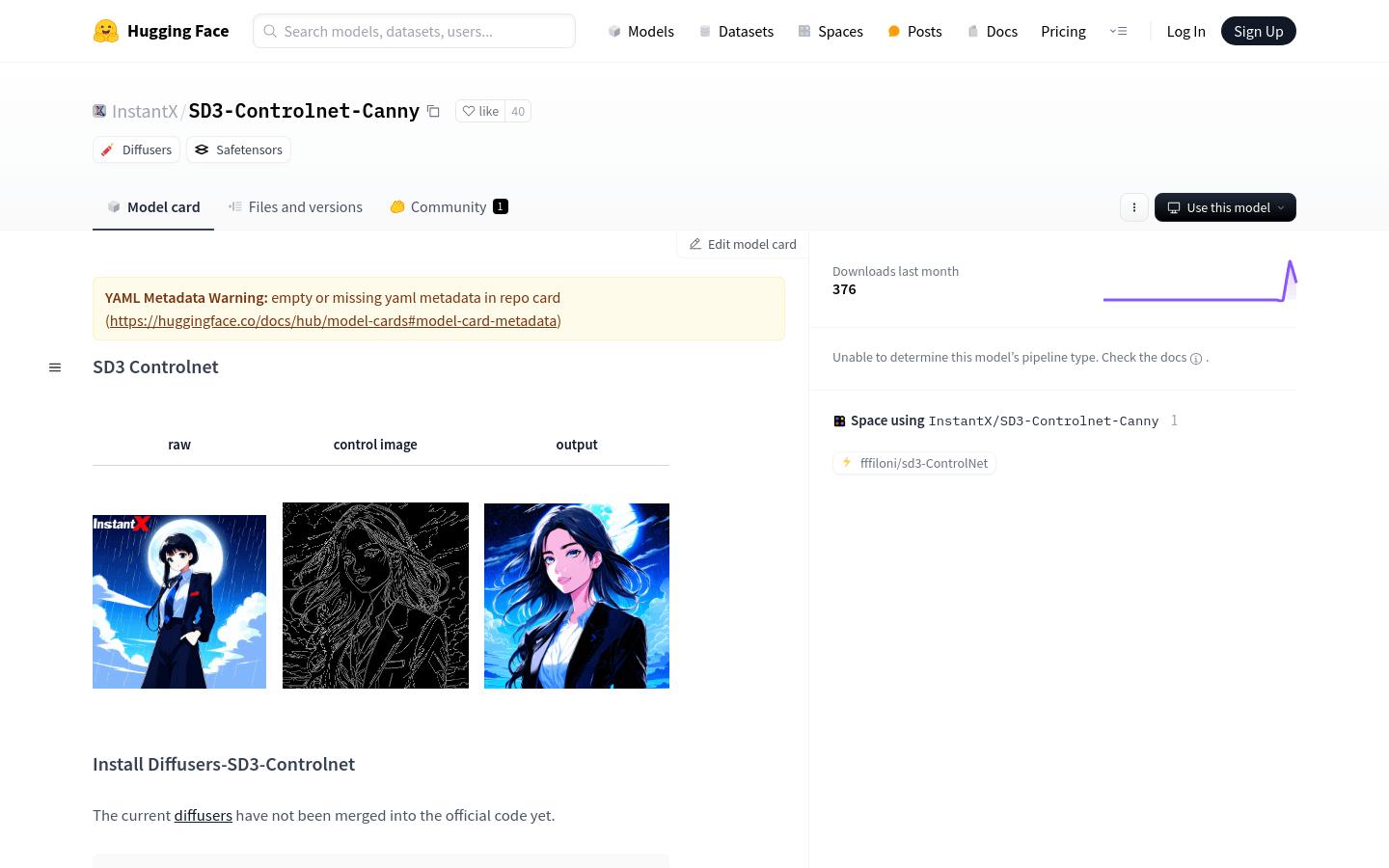

SD3-Controlnet-Canny
SD3-Controlnet-Canny 是一种基于深度学习的图像生成模型,它能够根据用户提供的文本提示生成具有特定风格的图像。该模型利用控制网络技术,可以更精确地控制生成图像的细节和风格,从而提高图像生成的质量和多样性。
需求人群:
“目标受众主要是图像生成领域的研究人员和开发者,以及对AI艺术创作感兴趣的艺术家和设计师。该模型能够帮助他们快速生成高质量的图像作品,提高创作效率。”
使用场景示例:
生成动漫风格的人物插画。
创建具有特定场景背景的图像,如带有月亮和暴风雨背景的图像。
定制化生成具有特定元素的图像,例如在图像中添加文本。
产品特色:
根据文本提示生成特定风格的图像。
使用控制网络技术精确控制图像细节。
支持多种图像生成参数,如引导比例和图像尺寸。
能够在GPU上运行,提高生成效率。
提供预训练模型,方便用户快速开始使用。
支持自定义控制图像,以影响生成结果。
使用教程:
1. 安装必要的库和依赖,如Diffusers-SD3-Controlnet。
2. 加载预训练的模型和控制网络配置。
3. 定义文本提示和负面提示,以指导图像生成的方向。
4. 设置控制网络的具体参数,如控制权重和控制图像。
5. 执行图像生成过程,调整生成步数和引导比例。
6. 获取生成的图像,并根据需要进行后续处理或展示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
















 龙跃AI 助手
龙跃AI 助手

