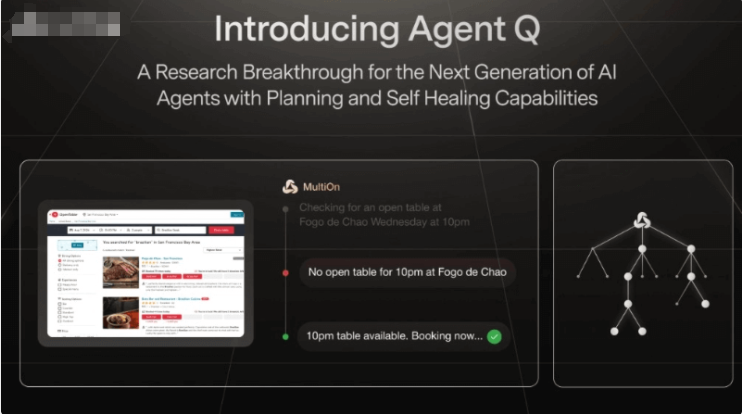
插图")
Mixture-of-Attention (MoA)
Mixture-of-Attention (MoA) 是一种用于个性化文本到图像扩散模型的新架构,它通过两个注意力路径——个性化分支和非个性化先验分支——来分配生成工作负载。MoA 设计用于保留原始模型的先验,同时通过个性化分支最小干预生成过程,该分支学习将主题嵌入到先验分支生成的布局和上下文中。MoA 通过一种新颖的路由机制管理每层像素在这些分支之间的分布,以优化个性化和通用内容创建的混合。训练完成后,MoA 能够创建高质量、个性化的图像,展示多个主题的组成和互动,与原始模型生成的一样多样化。MoA 增强了模型的先有能力与新增强的个性化干预之间的区别,从而提供了以前无法实现的更解耦的主题上下文控制。
需求人群:
“MoA 可用于个性化图像生成,特别是在需要在图像中嵌入特定主题并保持高质量和多样性的场景中。”
使用场景示例:
将用户上传的照片中的面孔替换为另一个人的脸
生成具有特定姿势和表情的个性化角色图像
在保持背景一致性的同时,通过改变初始随机噪声来生成不同主题的图像
产品特色:
个性化图像生成
主题和上下文解耦
高质量图像生成
多主题组合与互动
个性化分支和非个性化先验分支
像素分布优化
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END