
ViewDiff
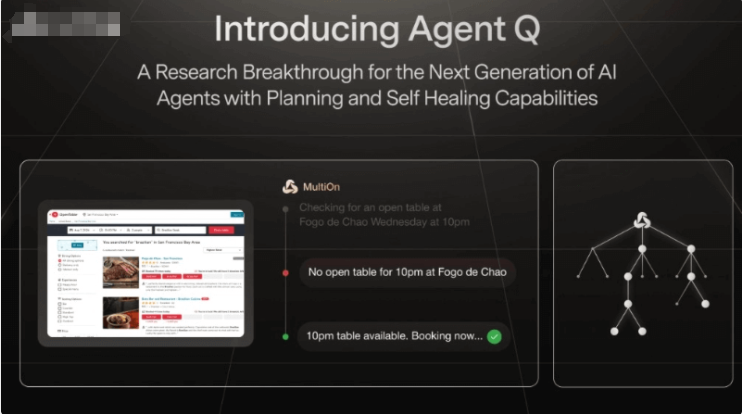
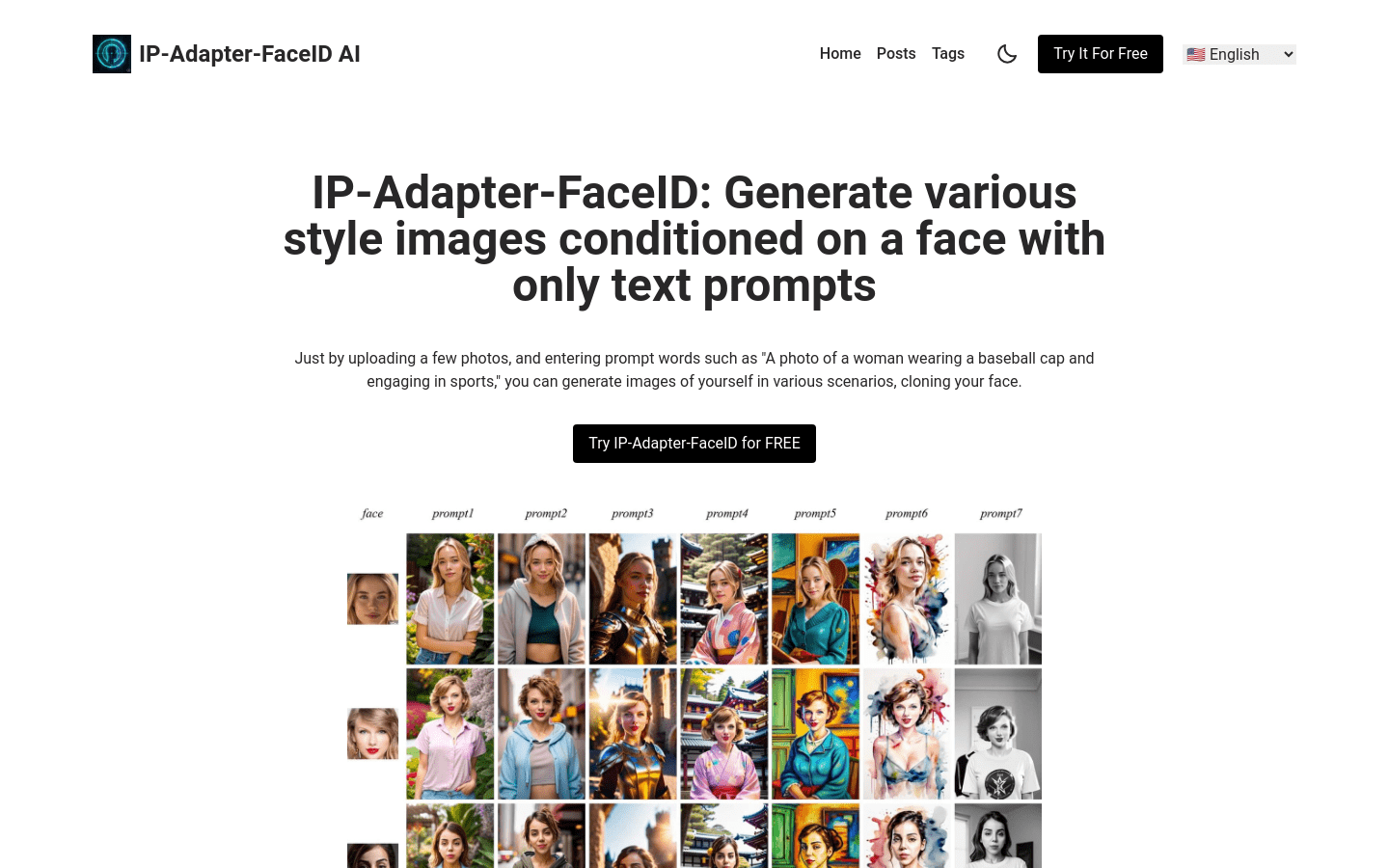
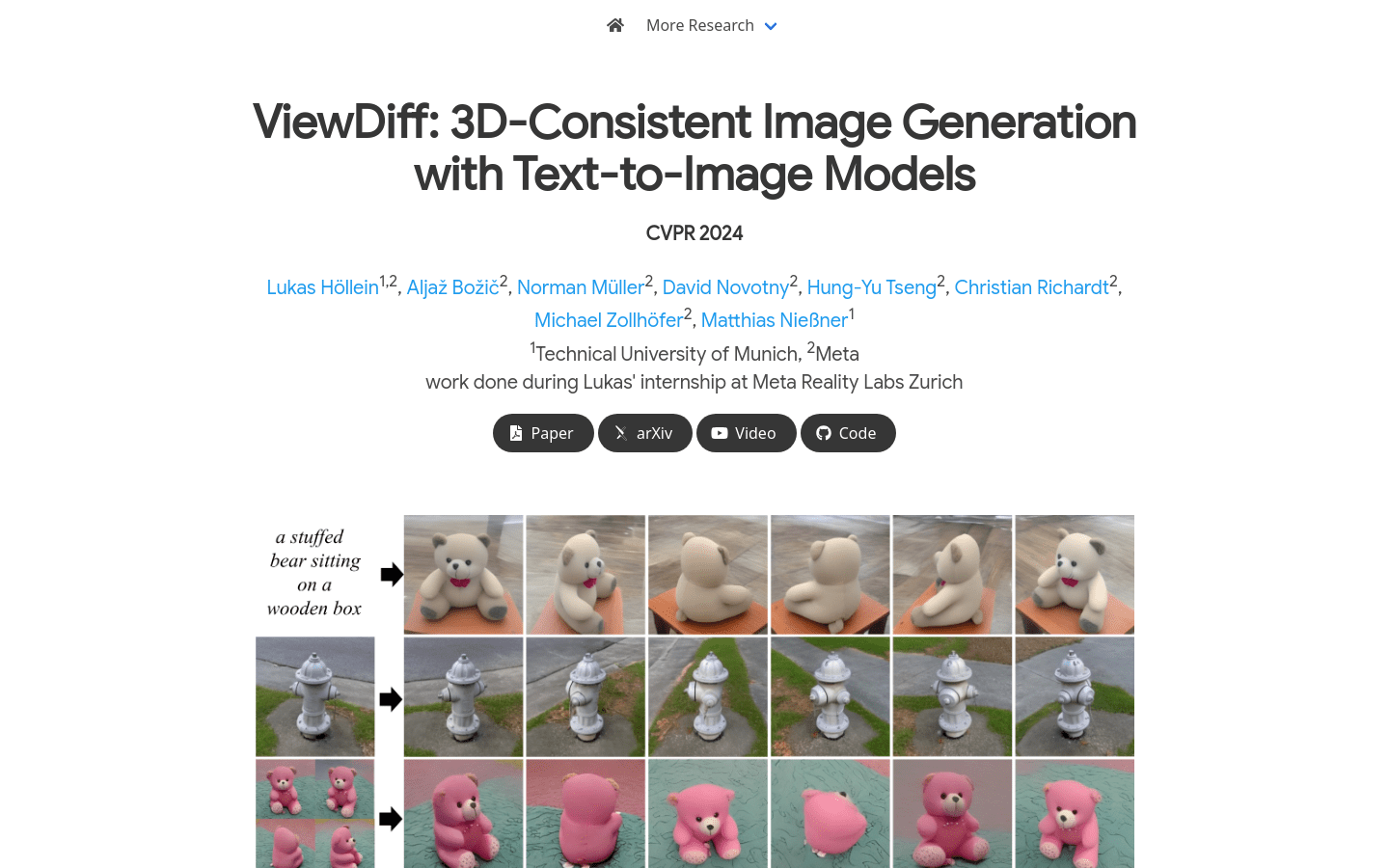
ViewDiff 是一种利用预训练的文本到图像模型作为先验知识,从真实世界数据中学习生成多视角一致的图像的方法。它在U-Net网络中加入了3D体积渲染和跨帧注意力层,能够在单个去噪过程中生成3D一致的图像。与现有方法相比,ViewDiff生成的结果具有更好的视觉质量和3D一致性。
需求人群:
“3D模型生成、图像合成、虚拟现实等应用场景”
使用场景示例:
生成各种形状和质地的3D物体图像,并将其置于真实世界环境中
根据文本描述生成一个3D物体的多角度图像
给定单个图像,生成该物体在不同视角下的图像
产品特色:
基于预训练的文本到图像模型生成3D一致的图像
在U-Net网络中加入3D体积渲染和跨帧注意力层
单个去噪过程中生成多视角一致的图像
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END