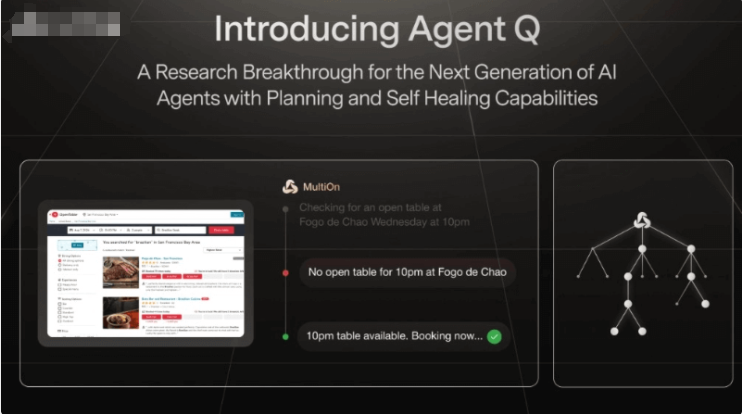
MiniGemini
Mini-Gemini是一个多模态视觉语言模型,支持从2B到34B的系列密集和MoE大型语言模型,同时具备图像理解、推理和生成能力。它基于LLaVA构建,利用双视觉编码器提供低分辨率视觉嵌入和高分辨率候选区域,采用补丁信息挖掘在高分辨率区域和低分辨率视觉查询之间进行补丁级挖掘,将文本与图像融合用于理解和生成任务。支持包括COCO、GQA、OCR-VQA、VisualGenome等多个视觉理解基准测试。
需求人群:
“Mini-Gemini可应用于需要同时处理文本和图像的各种场景,如视觉问答、图像描述生成、图像编辑等。”
使用场景示例:
根据给定的图像内容回答相关问题
生成图像的文字描述
根据指令对图像进行编辑生成新图像
产品特色:
低分辨率/高分辨率双视觉编码器
补丁级信息挖掘
基于大型语言模型的图文融合
支持视觉理解和生成任务
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END