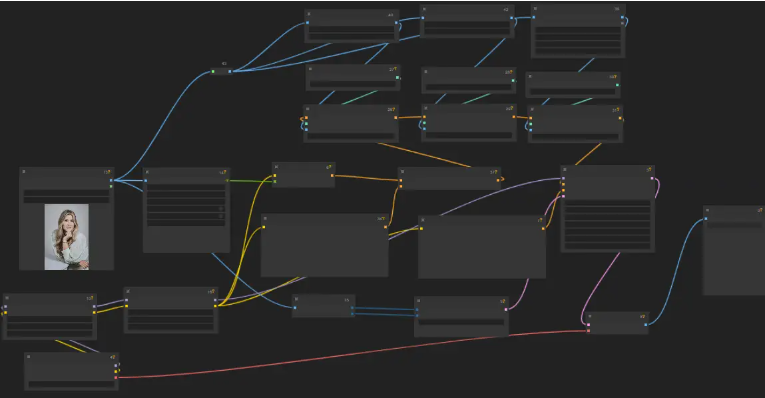
这个案例整合了我们之前所学的全部内容,非常适合
这个工作流使用 comfyui 来将照片转换为复古动漫风格的图像。以下是这个工作流中的各个节点及其功能的详细解析:
- 图像加载和预处理:
-
LoadImage (id: 13): 加载指定URL的输入图像。
-
DF_Get_image_size (id: 15): 获取加载图像的宽度和高度。
-
EmptyLatentImage (id: 5): 创建具有提取维度的空潜在图像。
- ControlNet加载器和预处理器:
-
ControlNetLoader (id: 28): 加载用于线稿的ControlNet模型 (
control_v11p_sd15_lineart.pth)。 -
ControlNetLoader (id: 30): 加载用于姿态检测的ControlNet模型 (
control_v11p_sd15_openpose.pth)。 -
ControlNetLoader (id: 27): 加载用于深度检测的ControlNet模型 (
control_v11f1p_sd15_depth.pth)。 -
Zoe_DepthAnythingPreprocessor (id: 40): 处理图像以生成深度信息。
-
Inference_Core_LineArtPreprocessor (id: 42): 处理图像以生成线稿信息。
-
OpenposePreprocessor (id: 39): 处理图像以生成姿态关键点。
- 条件应用和组合:
-
ControlNetApply (id: 26, 29, 31): 应用ControlNet条件到图像上,结合深度、线稿和姿态信息。
-
ConditioningCombine (id: 37): 组合不同的条件信息。
- 文本编码:
-
CLIPTextEncode (id: 6): 对正面描述文本进行编码,例如“beautiful scenery nature glass bottle landscape, purple galaxy bottle”。
-
CLIPTextEncode (id: 7): 对负面描述文本进行编码,例如“Easy Negative, worst quality, low quality”等。
-
CLIPTextEncode (id: 34): 对额外描述文本进行编码,例如“official art, context art, retro anime, complex background, blurry background, depth of field”。
- 模型加载和采样:
-
CheckpointLoaderSimple (id: 4): 加载主要的生成模型 (
AWPainting(1.4))。 -
LoraLoader (id: 10, 16): 加载Lora模型用于特定风格的调整(例如“80’sFusion(V2.0)”和“Retro Anime(1.0)”)。
-
KSampler (id: 3): 使用KSampler进行潜在图像的采样,结合模型、正面和负面条件以及潜在图像。
-
VAEDecode (id: 8): 将采样后的潜在图像解码为最终图像。
- 图像保存:
-
SaveImage (id: 9): 保存生成的图像。
使用说明
由于ComfyUI工作流比较复制,所以我这里直接提供工作流,并对重点进行解释说明帮助大家梳理逻辑。需要这个工作流的可以扫右边二维码加群获取哦,大家如果有哪里看不明白也可以加群交流。

第一次使用工作流可能会报错提示安装缺失节点,我们在管理器中把缺失的节点安装上即可

加载Lora
大模型串联两个Lora

反推标签
没有WD14 反推提示词的小伙伴可以在管理器中搜索WD安装即可,clip文本编码要改成以文本输入才可以和WD反推出的关键词连接

ControlNet控制
这边用到三个controlnet串联分别是,深度图,线稿,和姿态控制。

获取图片宽高

合并提示词
由于我们的Lora模型需要一些触发词,但是之前的文本编码器已经和WD连接,所以我们只能在复制一个文本编码器和WD提示词的文本编码器合并。最后把合并的条件连接到第一个controlnet应用

工作流效果


该工作流的主要步骤是通过加载和预处理图像,应用不同的ControlNet模型生成辅助信息(如深度、线稿和姿态),然后结合这些信息以及文本描述进行图像生成,最终解码并保存生成的复古动漫风格图像。需要这个工作流的可以扫右边二维码加群获取哦