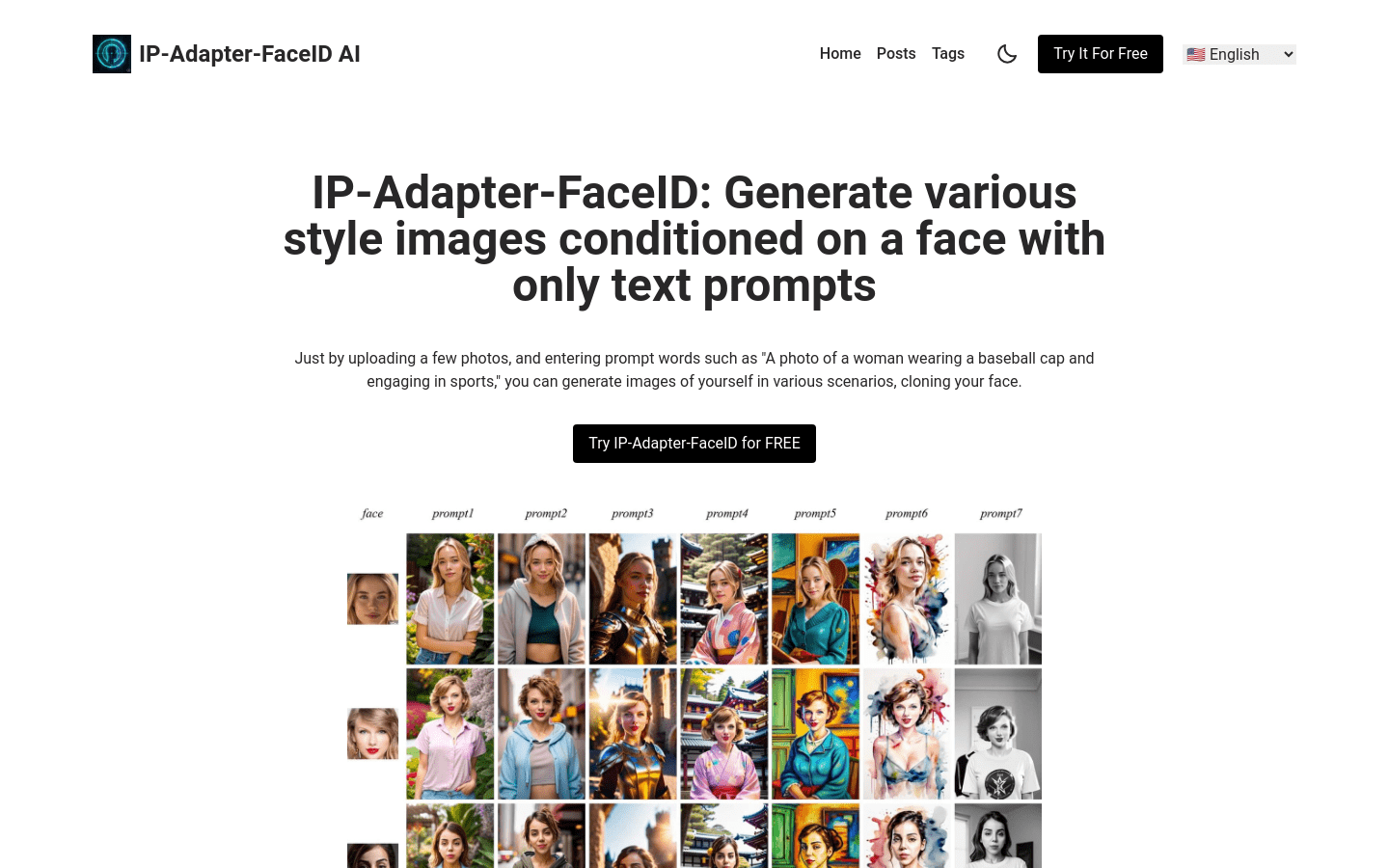
2024 年 4 月,Meta 推出了其下一代最先进的开源大型语言模型Llama 3。前两个模型 Llama 3 8B 和 Llama 3 70B 为同等规模的 LLM 树立了新的标杆。然而,短短三个月内,其他几款 LLM 的表现就超过了它们。
Meta 已经透露,其最大的 Llama 3 模型将拥有超过 4000 亿个参数,并且仍在训练中。今天,LocalLLaMA subreddit 泄露了即将推出的 Llama 3.1 8B、70B 和 405B 模型的早期基准测试。泄露的数据表明,Meta Llama 3.1 405B 可以在几个关键的 AI 基准测试中胜过目前的领导者 OpenAI 的 GPT-4o。这对开源 AI 社区来说是一个重要的里程碑,标志着开源模型首次可能击败目前最先进的闭源 LLM 模型。
Meta 在 Llama 3 发布会上发表了如下言论:
我们致力于不断发展和发展开放的人工智能生态系统,以负责任的方式发布我们的模型。我们一直坚信开放会带来更好、更安全的产品、更快的创新和更健康的整体市场。这对 Meta 有利,对社会也有利。

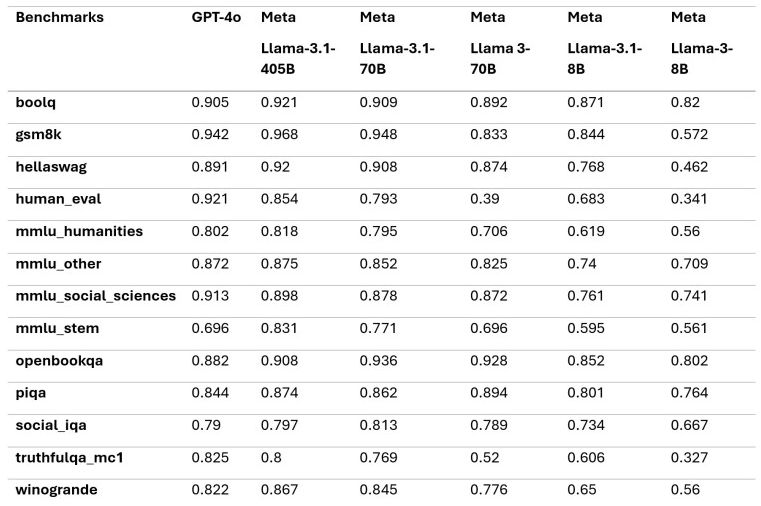
如基准测试所示,Meta Llama 3.1 在多项测试中的表现优于 GPT-4,包括 GSM8K、Hellaswag、boolq、MMLU-humanities、MMLU-other、MMLU-stem 和 winograd 等。然而,它在 HumanEval 和 MMLU-social sciences 方面落后。
值得注意的是,这些数字来自 Llama 3.1 的基础模型。要充分发挥模型的潜力,指令调整非常重要。随着 Llama 3.1 模型的 Instruct 版本的发布,许多结果可能会得到改善。
尽管 OpenAI 即将推出的 GPT-5 及其预期的高级推理能力可能会挑战 Llama 3.1 在 LLM 领域的潜在领导地位,但 Llama 3.1 在 GPT-4o 方面的强劲表现仍然凸显了开源 AI 开发的力量和潜力。这一持续进步可能会使尖端 AI 技术的获取变得民主化,并加速技术行业的创新。