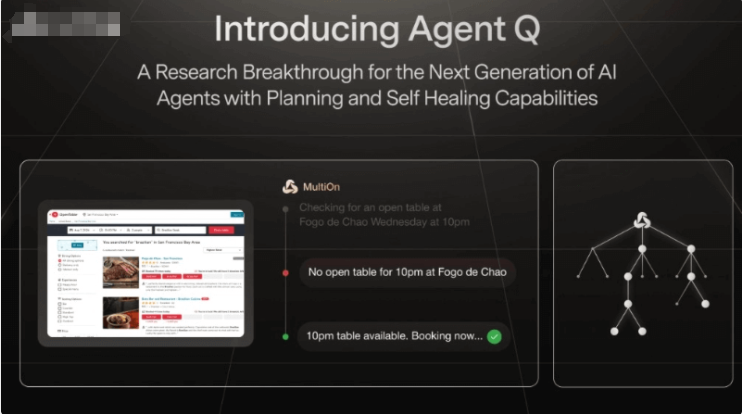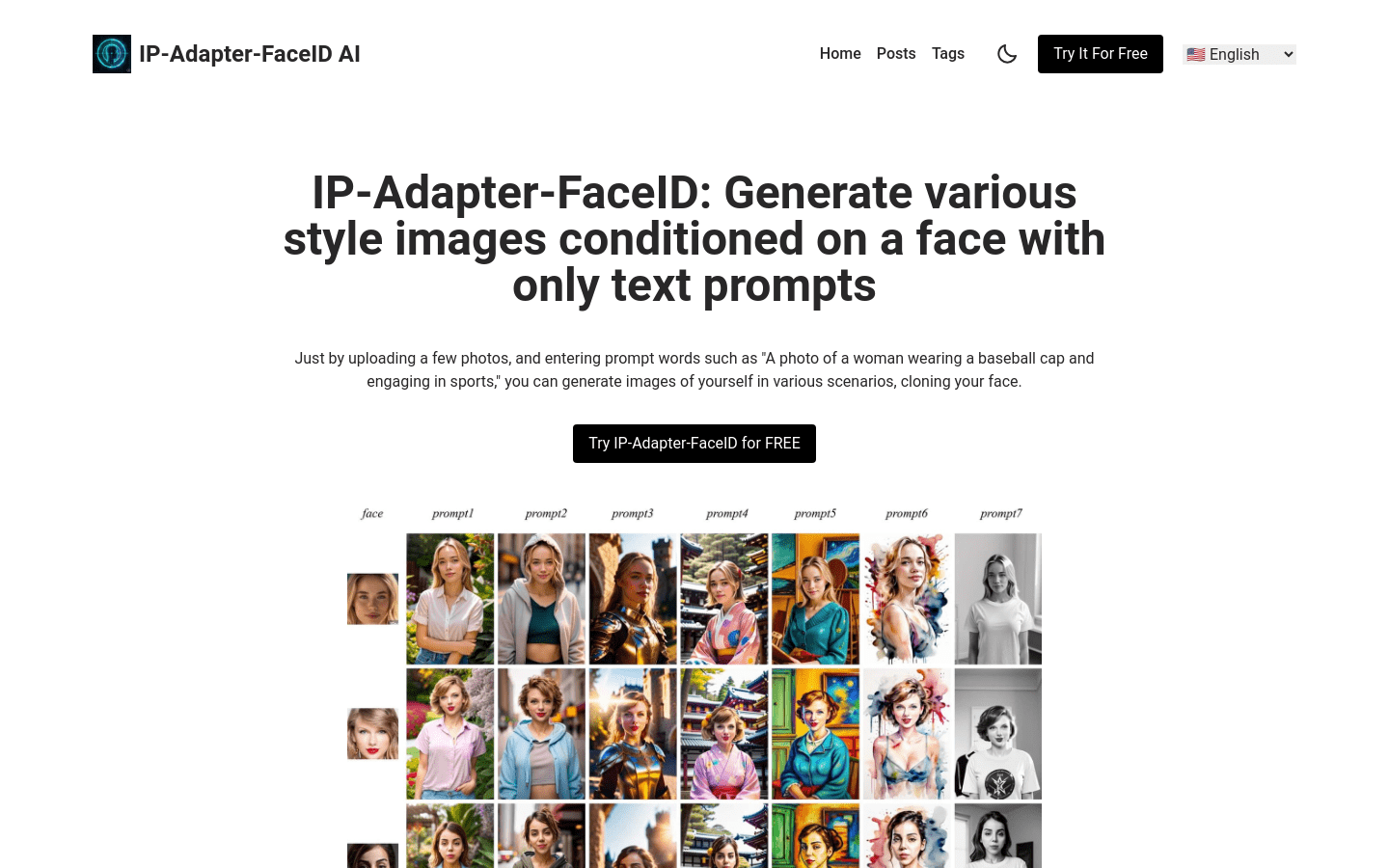

Omost
Omost是一个旨在将大型语言模型(LLM)的编码能力转化为图像生成(更准确地说是图像组合)能力的项目。它提供了基于Llama3和Phi3变体的预训练LLM模型,这些模型能够编写代码以使用Omost的虚拟Canvas代理来组合图像视觉内容。Canvas可以由特定的图像生成器实现来实际生成图像。Omost项目背后的技术包括Direct Preference Optimization (DPO)和OpenAI GPT4o的多模态能力。
需求人群:
“Omost的目标受众主要是对人工智能图像生成技术感兴趣的开发者、研究者和艺术家。它适合那些希望探索和实现创意图像概念,但可能不具备相应技术背景或资源来从头开始开发图像生成系统的人。”
使用场景示例:
艺术家使用Omost根据文本描述生成独特的艺术作品。
游戏开发者利用Omost快速生成游戏内的概念艺术和环境背景。
市场营销团队使用Omost创建吸引人的广告图像和社交媒体帖子。
产品特色:
支持多种数据混合训练,包括Open-Images等公开数据集的地面真实注释。
提供3种基于Llama3和Phi3的预训练LLM模型。
Canvas代理能够渲染图像生成器特定的实现来实际生成图像。
支持Conversational Editing,允许用户与模型进行对话以生成图像。
用户可以通过HuggingFace空间或自行部署来使用Omost。
提供了详细的API文档和示例代码,方便开发者和研究者使用。
使用教程:
访问Omost的GitHub页面以了解项目详细信息。
阅读文档以理解如何部署和使用Omost模型。
根据需要选择合适的预训练模型并进行配置。
使用Canvas代理和提供的API编写代码以生成图像。
通过与模型的交互进行Conversational Editing来细化图像生成结果。
将生成的图像应用于所需的项目或进一步的创意工作中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END