
CelebV-Text
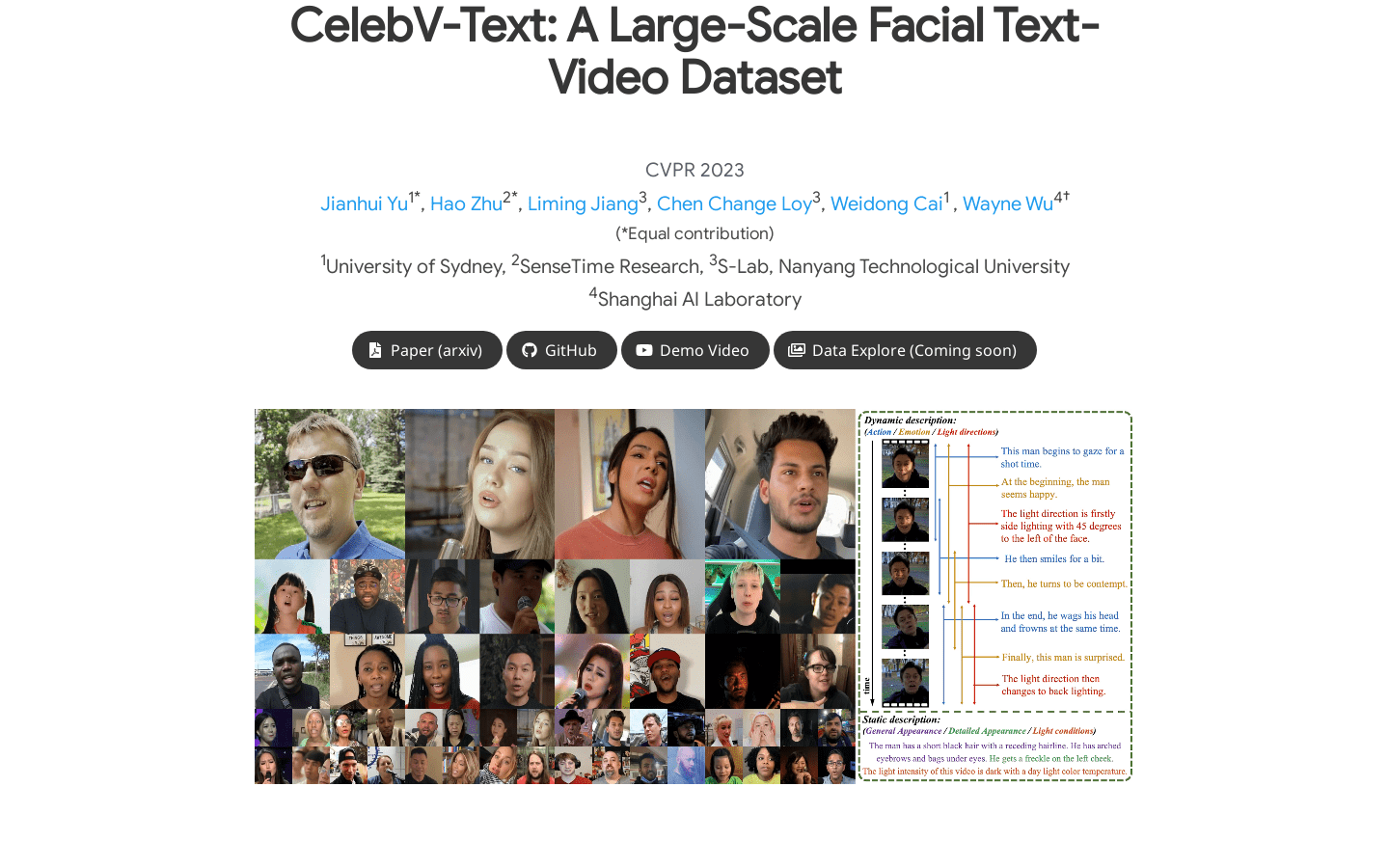
CelebV-Text是一个大规模、高质量、多样化的人脸文本-视频数据集,旨在促进人脸文本-视频生成任务的研究。数据集包含70,000个野外人脸视频剪辑,每个视频剪辑都配有20个文本,涵盖40种一般外观、5种详细外观、6种光照条件、37种动作、8种情绪和6种光线方向。CelebV-Text通过全面的统计分析验证了其在视频、文本和文本-视频相关性方面的优越性,并构建了一个基准来标准化人脸文本-视频生成任务的评估。
需求人群:
“用于人脸文本-视频生成任务的研究”
使用场景示例:
使用CelebV-Text数据集进行人脸文本-视频生成任务的研究
使用CelebV-Text数据集进行人脸文本-视频相关性分析
使用CelebV-Text数据集构建人脸文本-视频生成任务的基准
产品特色:
大规模人脸文本-视频数据集
70,000个野外人脸视频剪辑
每个视频剪辑都配有20个文本
涵盖40种一般外观、5种详细外观、6种光照条件、37种动作、8种情绪和6种光线方向
全面的统计分析验证数据集的优越性
构建了一个基准来标准化人脸文本-视频生成任务的评估
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END















 龙跃AI 助手
龙跃AI 助手

